
Connect Tableau with R – Get Beauty with Power
Tableau, as we all know, is the go-to tool for visualization, today. R is an open-source statistical language used by academicians, statisticians, data analysts and data scientists to develop machine learning models. R’s success must be owed to the power of its packages.
Why connect Tableau with R?
An analytics tool can generate enormous value if it has the following aspects:
- a user-friendly interface for a business user &
- scope and power to run different analyses and deliver the results to the interface in an easily interpretable way for the business user to understand and take decisions.
Tableau can be used to develop beautiful dashboards which can serve as a very good user interface. R can be used to develop and run complex machine learning models, behind the hood, whose results can be displayed in Tableau dashboards in an easily interpretable way.
In short, by linking Tableau and R, you are giving the business users the opportunity to create enormous business value by running and analyzing the results of complex machine learning models without having knowledge or experience in R!
How to connect Tableau with R?
- Install Rserve package and run Rserve command by typing the following lines in your R console:
install.packages(“Rserve”)
Rserve()
Now, R should print ‘Starting Rserve…’. If you got this, then R is reaching out to Tableau for connecting.
- Open Tableau & click on Help > Settings & Performance > Manage External Service Connections.
- In the dialog box that opens, choose ‘localhost’ for Server and type ‘6311’ for Port.
- Then, click on Test Connection
Now, you should get a dialog box stating, ‘Successfully connected to the R serve service’. If you got this, you are all set to use the power of R from within Tableau.
Objective of this article
All companies maintain a database containing details about their customers. Customer Segmentation using clustering algorithms is a proven technique used by companies to understand its customers. This helps you offer targeted deals that convert better! The objective of this article is to create a dashboard where an executive from wholesale business can segment his customers using R from within Tableau, without having to know R Programming, just by clicking in the dashboard. Then, visualize the different customer segments to find patterns that can be used to make business decisions like providing incentives, discounts, etc.
Dataset used
The dataset for this can be downloaded in CSV format from UCI Machine Learning repository by clicking on ‘Data Folder’ link at the top left of the page. In this dataset, each row contains details about a customer of the Wholesaler regarding his channel, region and the dollar amount spent by him on different product categories like Fresh, Frozen, Grocery, Milk, Detergent Paper & Delicassen. This dataset can be mined to understand the buying patterns/characteristics of customers based on their spending.
Designing a Customer Segmentation dashboard in Tableau
Loading data into Tableau
Open the CSV file, add a column named ‘Customer ID’ and fill it from 1 to 440.
Connect to the CSV file using the ‘Text File’ option in Tableau and you should see the below screen in your Tableau worksheet.

Creating Parameters
Let’s cluster users based on their spending in different categories using k-means clustering algorithm. K-Means is a unsupervised learning algorithm that identifies clusters in data based on similarity of features used to form the clusters. In our case, these features would be the customers spending in different categories.
K-means algorithm requires the following two inputs for it to form clusters: (1) the number of clusters to be formed & (2) How many times to run the algorithm before picking the best clusters. Basically, the K-Means algorithm takes as many random center points as specified by the user in input 1 and starts assigning the data points to these center points based on the criteria defined to calculate distance. Once all points are assigned, it measures the Sum of Squared Errors (SSE). This process is repeated as many times as specified in input 2. Then, the model with the least SSE is picked and shown as the result.
Let’s give the option of specifying the number of clusters to be formed to the user who is going to use the dashboard by creating a Tableau parameter. To do that, right click on the Measures pane and click on ‘Create Parameter’. Fill the Create Parameter dialog box with details as shown below and click OK.
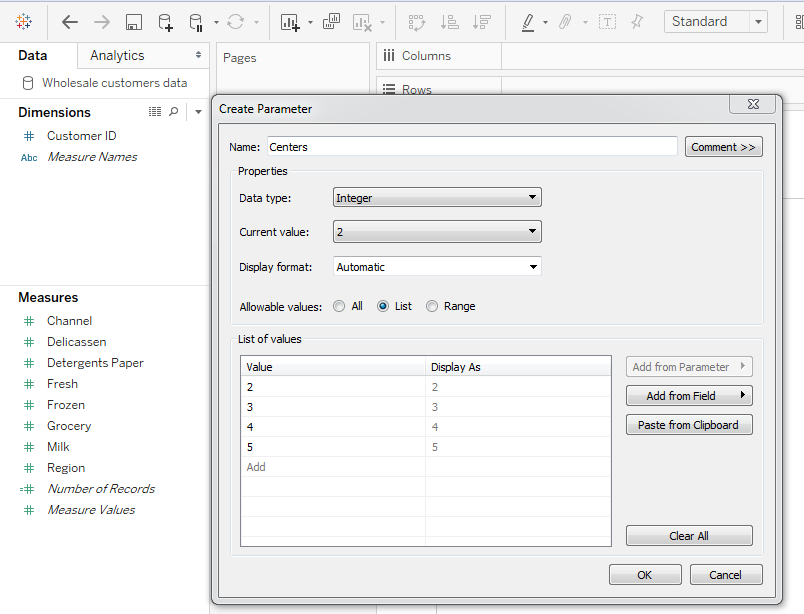
Right click on the newly created ‘Centers’ parameter and select ‘Show Parameter Control’ and set Centers value to 5.
For our results to be reproducible, we need to ‘set seed’ in R. The seed defines the random numbers generated that are used in the algorithms. So, whenever we set the same seed and run a model, we would get the same results. Let us give this option of defining the seed also to our user by creating a parameter as follows:

Right click on the newly created ‘Seed’ parameter and select ‘Show Parameter Control’ and set seed value to 500. Now, your screen should look like this:

SCRIPT functions to receive data from R
Now, to segment customers into different clusters, we are going to pass data to R, cluster it and get the results back in a Calculated Field that can be used in Tableau Visualizations. Tableau has four scripting functions which are related to the type of data they would receive from the external service Tableau is connected to. They are SCRIPT_REAL, SCRIPT_INT, SCRIPT_BOOL & SCRIPT_STR.
The syntax of a Script function is as follows:
SCRIPT_XXX (‘code to be executed as a string’, argument 1, argument2, etc.)
The arguments are referred as ‘.arg1’, ‘.arg2’, etc. respectively inside the code. All the arguments whether quantitative or categorical should be passed as aggregated versions to R since this is a table calculation. Since all our variables are quantitative, we aggregate them using the SUM function. The last line of the code in string would be returned as an output of the function by R to this calculated field.
So, let’s create a Calculated Field named ‘Cluster_kmeans’ with the following code in it and click OK:
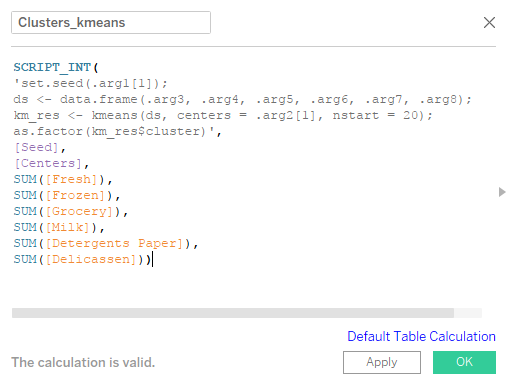
Briefly, the above code does this:
- Line 1: Sets seed, so that the results can be regenerated again if needed. As already said, K-means choses the center points at random and starts assigning data points to these cluster centers. The clustering results will change if these center points change. So, seed is used to define the random numbers generated so that if you set the same seed and run, the same center points will be taken up for clustering.
- Line 2: Combines all features (i.e. the customer spends in each category) that must be used for clustering into a data frame.
- Line 3: Runs the k Means model 20 times, in the above generated data frame, with as many cluster centers as specified by the user in the dashboard.
- Line 4: The best model out of the above 20 is picked and its results are returned to the Cluster_kmeans calculated field in Tableau, which can be used in visualizations.
We pass 8 arguments to the Script function. First is Seed, second is Centers (as in the number of clusters that we want k-means algorithm to form for this data) and the remaining 6 are the spend in each category. The six spend arguments are vectors of 440 dollar amounts each (as there are 40 customers in our dataset).
What is interesting is, the Seed and Centers parameters are also passed as vectors of length 440, but of the same value. i.e. Seed has ‘500’ repeated 440 times. In R, we pass a single number as seed, not a vector of length more than 1. So, we extract the first element of the vector alone and pass it to ‘set.seed’ function as follows:
Set.seed(.arg1[1])
Similarly, to the centers argument of k-means algorithm also we pass only a single value. If given a single value, the algorithm generates that many number of random centers and starts assigning points to clusters. If you give a vector to this argument, then it takes the values in the vector as the spatial location of center points and starts assigning points to clusters. Now, if you pass a vector of length 440 where all values in the vector being the same, then you would get an error as follows:
Error in kmeans(ds, centers = .arg2, nstart = 20) : initial centers are not distinct
To avoid this, we extract the first element of the vector alone and pass it to ‘kmeans’ function as follows:
km_res <- kmeans(ds, centers = .arg2[1], nstart = 20)
Visualizing the clusters created by R
Now that the calculated field for clusters is created, we can start creating the visualization shown in the figure below. Before that, go to Analysis > Aggregate Measures and turn it off. Because, if you don’t, Tableau will aggregate all the spend for all customers and send a single row of input to R, resulting in the following error. This error says there are more than one center points to start with and only one data point that can be assigned. Hence, the clustering cannot be completed.
Error in kmeans(ds, centers = .arg2[1], nstart = 20) : more cluster centers than distinct data points
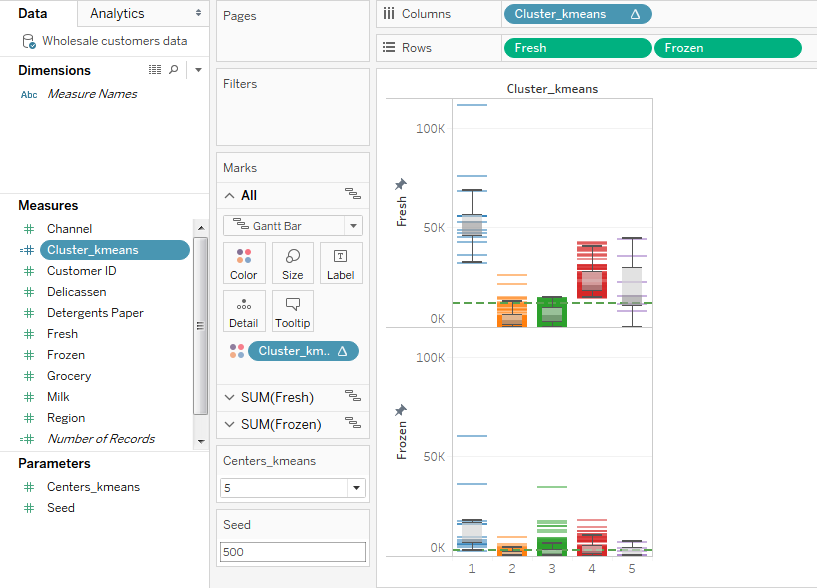
This sheet describes the spend of each cluster in Fresh and Frozen categories. To create the above visualization in Tableau, do the following:
- Drag and drop ‘Cluster_kmeans’ into ‘Columns’ shelf and into Color
- Drag and drop ‘Fresh’ and ‘Frozen’ into ‘Rows’ shelf
- Set the chart type to ‘Gantt Bar’
- From ‘Analytics’ tab at the top left, drag and drop ‘Box Plot’ into ‘Cells’ of the chart
- From ‘Analytics’ tab at the top left, drag and drop ‘Average Line’ into ‘Panes’ of the chart
- Adjust Opacity in the color palette by setting it to 50%
- Fix the Y-axis of the graphs to read from 0 to 115,000 so that it would be easier to compare across all the six charts we are going to develop for the dashboard. ( I chose 115,000 as the upper limit, because the max spend by a single customer in a single category is of the order of 112k)
- You can adjust the tooltip to reflect the information that you deem necessary/relevant at this point.
Now, similarly create two other worksheets which would look as follows:
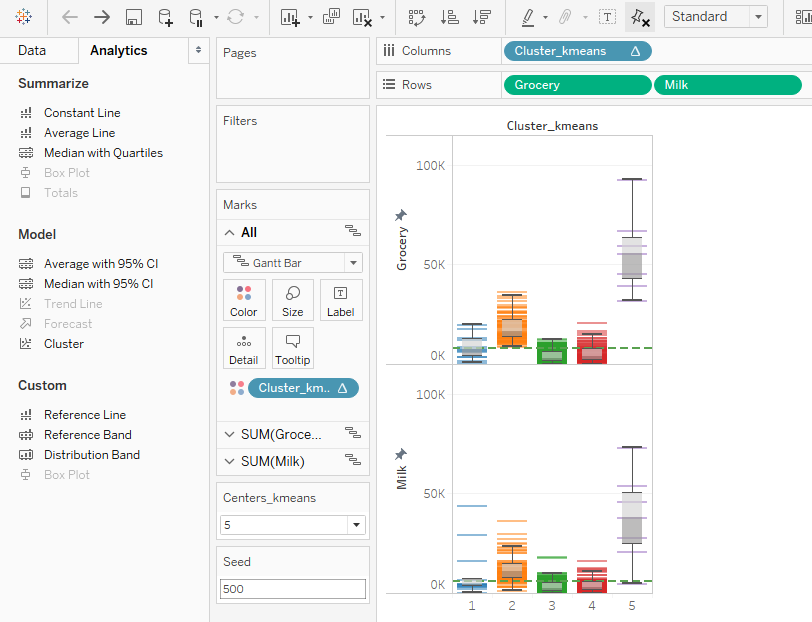
This sheet describes the spend of each cluster in Milk and Groceries categories.

This sheet describes the spend of each cluster in Delicassen and Detergent Paper categories.
Creating Customer Segmentation Dashboard
Create a new dashboard and drag all three worksheets you created into the dashboard. Arrange the parameter controls and chart legends appropriately. Use blank containers to fill space if needed. Now your dashboard may look like this.

So now, we have put together a dashboard where a business user (in this case, the Wholesaler) can choose how many clusters he wants to form from his customer data and understand about the different clusters formed. The cluster results generated are always reproducible if the user inputs the same seed again (in this case 500).
Recalculating Clusters at the Snap of your Fingers!
To change the number of clusters from 5 to any other value, all the user must do is to change the number in the Centers parameter list box. Tableau will pass the updated parameter to R, clusters will be re-calculated through Table calculation in R, and the dashboard will be updated to reflect the new cluster details! The below image shows the dashboard when the Centers is changed from 5 to 3.

Features of this Customer Segmentation Dashboard
Since, we fixed all Y axis to the same range, these charts are comparable across too.
The Gantt bar chart shows each customer as a bar in the chart. This will also help us identify if the clusters formed have too few customers in them (they will have very few bars) so that, we can be taking decisions keeping that in mind.
Hovering over the box plots in each pane will give details about the quantiles of spending by the respective cluster in that respective category.
Clicking on a specific cluster in the chart legend at the right top will highlight only that cluster in the dashboard by dimming others and all the average lines in each category pane will be recalculated to show the average spend of this specific cluster in that category.
Interpreting Results and Taking Actions to Generate Business Value
We, at Perceptive Analytics, feel that the main aim of any business intelligence dashboard is to deliver insight and inspire action of the business users. Because, business value will not be created until any one of them acts on the insights! It is our (dashboard designer’s) job to make sure that the dashboard is designed in a way such that the business users does not have to spend more time searching for insights or trying to understand the dashboard. They should spend very less time in organizing data & more time in interpreting information / insights and creating / strategizing action plans.
Let’s now see what insights we can generate out of this dashboard with three clusters, shown above:
- The highest spend in registered by a customer in Fresh category (at the left top of the dashboard).
- Categories Fresh, Grocery, Milk and Detergents Paper have registered a decent number of spends above 20k dollars. So, these are the categories where the Wholesaler gets more money from his customers.
- Looking at the spending pattern of the three clusters formed in the above graph, I can gather the following:
- Cluster1 (Blue) seems to spend in all categories indifferently (In all categories, their spend is spread above and below the respective category average spend)
- Cluster2 (Orange) spends way above category averages in grocery, milk and detergents paper categories
- Cluster3 (Green) spends extra ordinarily in Fresh category and like Cluster1 in all other categories.
Within the same cluster, some customers purchase many items, others less. Recommendations can be provided to those who purchase less based on the missing items, compared to the customer who purchased more in the same category. Category related offer mails and discount mails can be targeted to those group of customers who actively purchase in that respective category.
Now, the wholesaler can create test and control groups within clusters and start sending targeted marketing campaigns to the customers in relevant segments. The test and control split would be useful to know if the campaigns are working or not. By continuously repeating this experiment of targeted marketing campaigns and analyzing the results after, the wholesaler can fine-tune himself to look for patterns in his customer data and know what kind of a marketing campaign will motivate them to purchase more.
Conclusion
In this article, we created a dashboard using which a business user can segment his customers and visualize the spending patterns of different clusters to understand the customers better. We leveraged the power of R to segment the customers from within Tableau itself. This knowledge can be used to take business decisions like offering trade discounts or targeted promotional offers.
Author Bio
This article was contributed by Perceptive Analytics. Sinna Muthiah Meiyappan contributed to this article.
Perceptive Analytics provides Tableau Consulting, data analytics, business intelligence and reporting services to e-commerce, retail, healthcare and pharmaceutical industries. Our client roster includes Fortune 500 and NYSE listed companies in the USA and India.